






Betejat për të drejtat e autorit kundër OpenAI kanë filluar – Artistë të ndryshëm ngrijnë padi kundër kompanive të AI

Dy novelistë, Paul Tremblay dhe Mona Awad, kanë ngritur një padi kundër OpenAI në një gjykatë federale në San Francisko, duke pretenduar se modeli i tij i gjuhës së ChatGPT ishte trajnuar duke përdorur të dhëna nga librat e tyre me të drejtë autori pa pëlqim.
Tremblay dhe Awad, pohojnë në padinë e tyre 16 faqeshe që ChatGPT gjeneron përmbledhje shumë të sakta të veprave të tyre letrare kur kërkohet.
Shkrimtarët thanë se kjo është "e mundur" vetëm nëse ChatGPT është trajnuar për përmbajtjen në librat e tyre, gjë që do të përbënte një shkelje të ligjit federal për të drejtat e autorit. Si rezultat, shtojnë ata, OpenAI qëndron të "përfitojë [në mënyrë komerciale] dhe të përfitojë shumë" nga përdorimi i materialeve të tyre me të drejtë autori. Andres Guadamuz, një studiues i pronësisë intelektuale në Universitetin e Susse, i tha Guardian se ky është pretendimi i parë ligjor i lidhur me të drejtat e autorit kundër OpenAI. Por ka shumë pak gjasa që të jetë i fundit.
A është OpenAI në telashe për përdorimin e materialit me të drejtë autori?
Ankesa e autorëve citon një punim të qershorit 2018, në të cilin OpenAI zbuloi se kishte trajnuar modelin e tij GPT-1 në BookCorpus, "një koleksion prej mbi 7,000 librash unikë të pabotuar nga një sërë zhanresh.
Në dokumentin e tij të korrikut 2020 që prezanton GPT-3, OpenAI zbuloi se 15% e të dhënave të tij të trajnimit vinte nga "dy korpora librash të bazuara në internet" që OpenAI i quajti thjesht "Books1" dhe "Books2". "Books1", thanë autorët në ankesën e tyre, është rreth nëntë herë më i madh se BookCorpus, ndërsa Books2 është 42 herë më i madh. Vetëm këto dy grupe të dhënash do të përmbajnë më shumë se 350,000 libra.
Që nga fillimi i ChatGPT nëntorin e kaluar, OpenAI nuk ka zbuluar kurrë se cilat të dhëna të sakta përdori për të trajnuar robotin, as burimin e atyre të dhënave. Në letrën e tij të vitit 2020, OpenAI thjesht tha se shumica e të dhënave të trajnimit përgjithësisht u fshinë nga uebfaqja, duke përfshirë librat e arkivuar dhe Wikipedia.
Le të fillojnë betejat për të drejtat e autorit të AI
Padia nga Tremblay dhe Awad inauguron një betejë midis pronarëve të të drejtave të autorit të veprave të përdorura për të trajnuar modele të mëdha gjuhësore dhe kompanitë e AI. Ai gjithashtu përforcon kërkesat e mëparshme për dëmshpërblime për veprat e përdorura pa pëlqim, pavarësisht vështirësive për të provuar se pronarët e të drejtave të autorit në fakt kanë pësuar humbje financiare nga këto shkelje.
Në janar, një grup artistësh vizualë paditën Stability AI, Midjourney dhe DeviantArt, duke argumentuar se këta motorë të AI përdorën veprat e artit të artistëve njerëzorë për të prodhuar imazhe në stilet e tyre. Dhe në maj, Ashley Irwin, presidente e Shoqatës së Kompozitorëve dhe Lirikut, i tha një nënkomisioni gjyqësor të Dhomës se të drejtat e autorit të krijuesve duhej të mbroheshin nga sistemet gjeneruese të AI.
Nëntorin e kaluar, programuesit kompjuterikë ngritën një padi prej 9 miliardë dollarësh kundër Microsoft, faqes për ndarjen e kodeve GitHub dhe OpenAI. Padia argumentoi se Copilot, një asistent kodimi me AI në GitHub, përdor kodin e njerëzve të tjerë në një mënyrë që përbën piraterinë e softuerit. Copilot u akuzua për shkelje të të drejtave të autorit duke përdorur linja kodi të shkruara nga njerëz pa atribuimin e duhur.
Me këtë padi të fundit nga Tremblay dhe Awad, rregullatorët dhe gjykatat do të ngarkohen të shqyrtojnë rregullat e të drejtës së autorit në lidhje me AI. Ata mund të kërkojnë që kompanitë gjeneruese të AI të zbulojnë se si dhe ku i kanë marrë të dhënat e tyre të trajnimit, duke e lënë botën të shikojë brenda kutisë së zezë të këtyre sistemeve të AI për herë të parë.
SCAN

Dixhitalizimit të fondeve të BE-së – Audituesit e BE-së: Ende një punë në progres
Rishikimi i Gjykatës Evropiane të Auditorëve (ECA) i dixhitalizimit të fondeve të BE-së, i publikuar të enjten (6 korrik), përshkroi peizazhin aktual të......
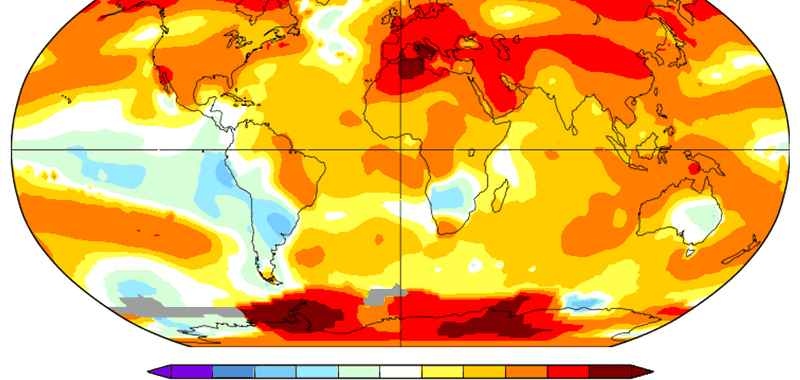
Toka vuan javën më të nxehtë në histori – Edhe Antarktida kalon 4.5°C mbi normalen
Shifrat e fundit ndihmojnë në vërtetimin se "ndryshimi i klimës është jashtë kontrollit", thotë Sekretari i Përgjithshëm i OKB-së Antonio Guterres. Toka......

Kursi i këmbimit – Euro, dollari dhe paundi sërish në rënie
Dollari amerikan e ka nisur ditën e sotme duke regjistruar një rënie të lehtë të vlerës teksa blihet sot me 95.1 lekë dhe shitet me 96.1 lekë sipas kursit të......

Uniformizohen pikat doganore të Shqipërisë. Rikualifikim dhe elemente identifikues për secilën pikë tokësore
Të gjithë pikat kufitare të Shqipërisë i janë nënshtruar rikualifikimit, falë një projekti që ka bashkuar Ministrinë e Turizmit, Kulturës dhe Ministrinë e......

Portugalia ndalon muzikën e lartë në plazh – Gjobat për shkelje shkojnë deri në 36 mijë euro
Pushuesit e plazhit në Portugali janë paralajmëruar se mund të përballen me gjoba deri në 36,000 euro për vendosjen e muzikës me zë të lartë. Altoparlantët......

Turi ballkanik - Rama dhe Kryeministi i Maqedonisë së Veriut Dimitar Kovačevski, konferencë për shtyp pas takimit bilateral në Shkup
Kryeministri Edi Rama po zhvillon një tur dy ditor në kryeqytetet e Ballkanit Perëndimor ku do të takohet me liderët e shteteve. Shkupi është ndalesa e parë e......

Kina përpiqet të mbështesë rënien e juanit – Monedha vendase bie në drejt nivelit më të ulët 14-vjeçar
Pekini po lufton për të treguar se mund të mbështesë juanin kinez, ndërsa ai bie drejt nivelit më të ulët të 14 viteve. Banka qendrore e Kinës dhe një......

Dëshironi të transferoheni në Danimarkë? - Ja vendet e punës të hapura për të punëtorët e huaj
Danimarka sapo ka përditësuar listën e saj të vendeve të punës të hapura për punëtorët e huaj. Nëse keni dashur gjithmonë të transferoheni në Evropë, nuk ka......

















